Python利用Last-Modified实现监控网页变化
工作需要实现监控一个网页的变化,一旦远程某个网页的代码或者内容更新了,马上发出提示。之前考虑过,抓取网页,保存网页,抓取-比对的方案,但是这样做不但访问的频率会受到限制,而且效率也很低。无法满足高效精准的要求。其实,根据浏览器的缓存原理,利用Last-Modified属性,可以做到高效且精准的监控。
Last-Modified属性技术原理:
在浏览器第一次请求某一个URL时,服务器端的返回状态会是200,内容是你请求的资源,同时有一个Last-Modified的属性标记此文件在服务期端最后被修改的时间,格式类似这样:
Last-Modified: Fri, 12 May 2006 18:53:33 GMT
客户端第二次请求此URL时,根据 HTTP 协议的规定,浏览器会向服务器传送 If-Modified-Since 报头,询问该时间之后文件是否有被修改过:
If-Modified-Since: Fri, 12 May 2006 18:53:33 GMT
如果服务器端的资源没有变化,则自动返回 HTTP 304 (Not Changed.)状态码,内容为空,这样就节省了传输数据量。当服务器端代码发生改变或者重启服务器时,则重新发出资源,返回和第一次请求时类似。从而保证不向客户端重复发出资源,也保证当服务器有变化时,客户端能够得到最新的资源。
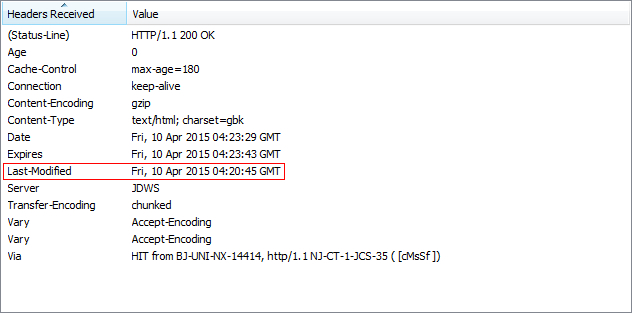
利用此属性,基本可以实现监控网页变化,在两秒钟之内如果网页发生变化,出现提示,代码如下:
# coding: UTF-8
# filename: moniter.py
import time
import requests
url = 'http://www.abc.com/test.html'
last_modified = ''
def get_page():
global last_modified
headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3',
'Connection':'keep-alive'
}
if last_modified:
headers['If-Modified-Since'] = last_modified
res = requests.get(url, headers = headers)
if res.status_code == 200:
if last_modified and last_modified is not res.headers['Last-Modified']:
print 'page has changed\r',
return False
last_modified = res.headers['Last-Modified']
elif res.status_code == 304:
print 'normal\r',
return True
if __name__ == '__main__':
while 1:
result = get_page()
if result:
time.sleep(2)
else:
break
未完,待续...
我是怎么进来的
是穿越来的吗
正好借用你网页测试测试,嘿嘿
sdfsdf
好像很多网页没有这个字段,比如博主这篇文章就没有,不知道有什么其他办法没
不错的思路,去尝试一下。
试一下
再试试
学习了,涨姿势啊!!